Review of the Data Umbrella Scikit-learn Online Sprint June 2020
Introduction
On 6 June 2020 I took part in an open source sprint organised by Reshama Shaikh of Data Umbrella and NYC PyLadies. The aim of the sprint was to help people from underrepresented groups in tech to contribute to the open source machine learning library scikit-learn and with that to also generally help people to contribute to open source projects.
The sprint was planned to be held in New York, however due to the Corona pandemic the decision had been made to turn it into an online event. This opened up the opportunity for people to participate remotely and in total 42 people from 10 countries and 5 continents (Africa, North and South Americas, Asia, and Europe) joined the sprint.
My motivation behind taking part in the sprint
I use open source software on a daily basis in my personal and professional life. It has made my research studies more transparent, advanced my professional skills, and allows me to work more efficiently. Open source software, including the scikit-learn library, plays an important role in my life and I would like to use my skills to give back and help with improving the software I depend on.
Another aspect is that as a representative of a minority group in tech (women), I would like to encourage more people of underrepresented groups in tech to participate in open source projects. I hope that my participation contributes to increasing the visibility of women in open source projects and that it encourages girls and women to break into tech.
Lastly, open source projects are a great place for practicing skills and building a professional portfolio while at the same time working for a good cause. I personally have never received formal computer science/ programming education and therefore to me open source projects are a valuable space where I can demonstrate my skills.
Getting to work
The sprint was organised via the platform Discord. Participants were assigned a programming partner and for each team there was a channel for written communication and an interactive channel where people could share their screen and chat to each other. The interactive channel also allowed the organisers/ core developers to jump in and help if needed. Additionally, there was a “help queue” channel where participants could ask questions and an interactive “help” channel where participants could talk directly to available mentors.
My programming partner and I have limited experience with contributing to open source projects and therefore selected an easy task to familiarise ourselves with the workflow. Our task was a stalled pull request that was almost ready to merge. A reviewer requested adding a few whitespaces to the code for consistency and improved readability. Making the suggested changes meant that we first had to pull from the stalled pull request. Once this was done, we made the requested changes. In order to check for style and programming errors, we then ran two tests with the tools flake8 and pytest, respectively.
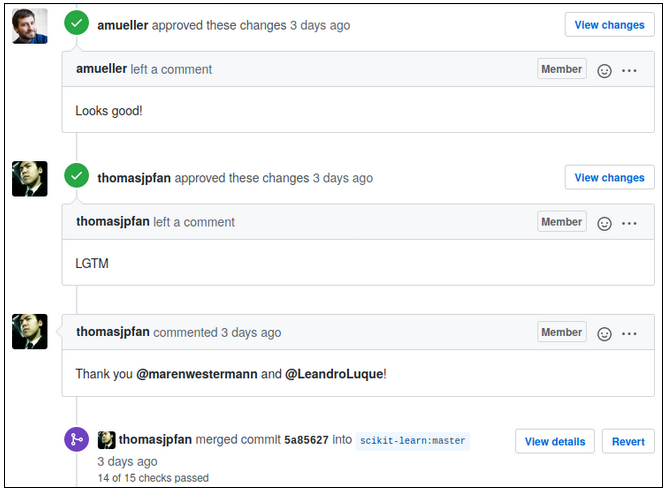
Both tests were successful, hooray! This meant that we were ready to make a pull request into the scikit-learn master branch. When a pull request into the scikit-learn master branch is made, several tests are run which can take a little while. Our tests were successful and there were no merge conflicts with the master branch. Our pull request got accepted and was merged into master shortly after the sprint.
Socialising
Even though the sprint was online it was possible to network. Towards the end of the sprint there was a “breakout” channel where people could have a chat. I enjoyed getting to know a bit other participants of the sprint and some of the organisers.
Summary
The sprint was very well organised. Preparatory material such as videos and written instructions were very helpful and were sent to participants well in advance. The Discord platform was easy to understand and use and allowed quick help and feedback from organisers and core developers.
The Data Umbrella and PyLadies organisers and scikit-learn team are friendly, supportive, professional and welcoming and by that created a motivating and enjoyable work environment during the sprint. Diversity is a major problem in tech and especially in open source projects. Giving priority to people from underrepresented groups (e.g. people of colour and women) and partnering with Data Umbrella and NYC PyLadies is a great initiative for increasing diversity in tech and open source projects. Through this sprint (as well as previous ones) the scikit-learn team leads by example in tackling this issue and will hopefully inspire other open source communities to follow suit.
I would like to thank everyone involved in organising and leading the sprint for their time and support. I am very happy about having found this warm and open online community and I will definitely stay involved and help with improving the scikit-learn library.
Outlook
For people who are interested in contributing to open source projects in general or to the scikit-learn library specifically, the organising team has put together excellent resource material which is available here. Furthermore, instructions on how to contribute to the scikit-learn library can be found on the official scikit-learn website.